
Abstract
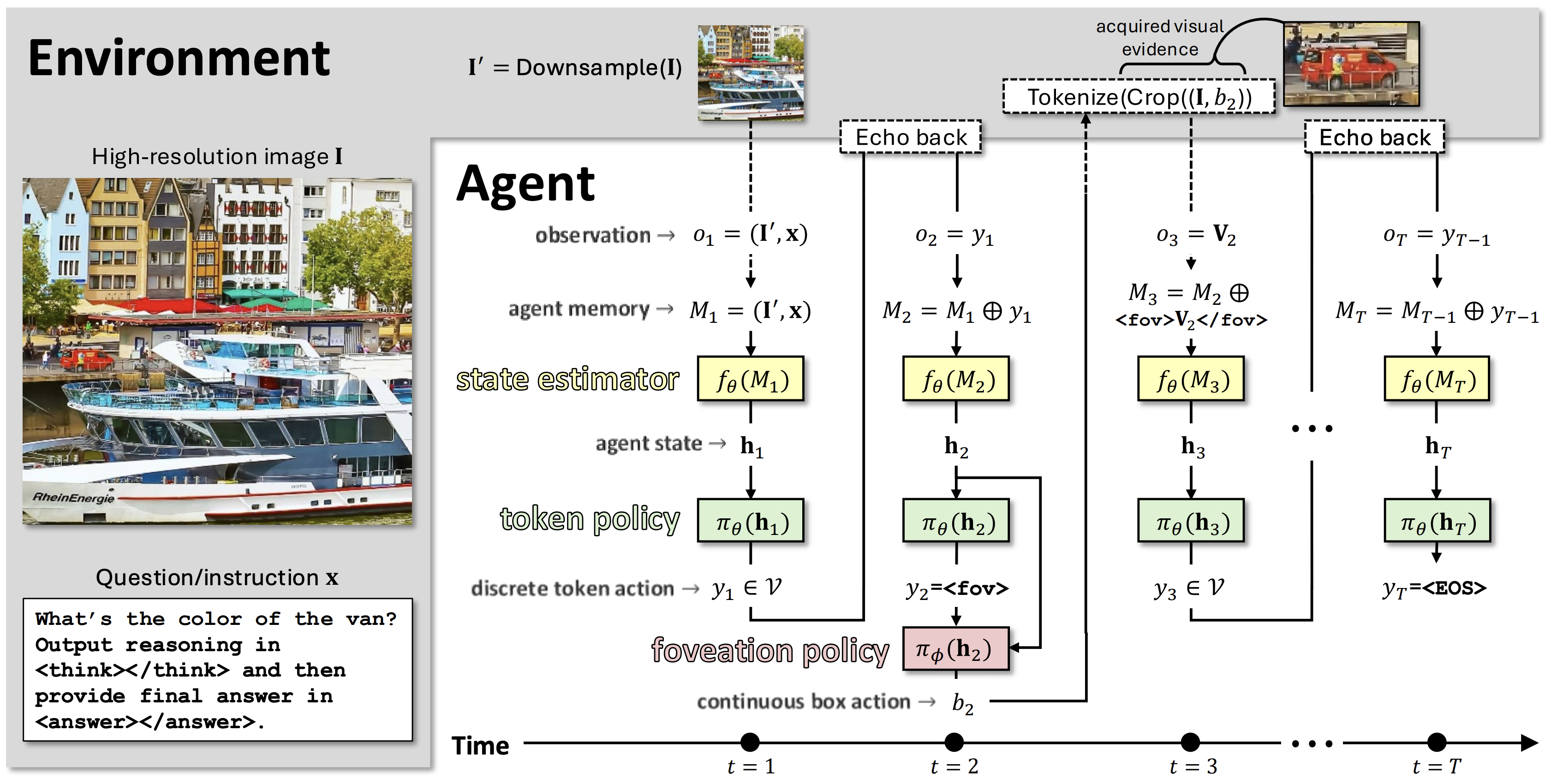
We introduce Foveated Reasoning, a vision-language reasoning framework that enables a model to adaptively focus on task-relevant visual regions while generating its reasoning trajectory. Instead of processing the entire image at uniformly high resolution, the model starts from a low-resolution view, emits textual reasoning tokens, and selectively triggers foveation actions to retrieve high-resolution evidence only when needed in a single autoregressive decoding trajectory.
Stateful Reasoning
The model maintains a hidden interaction state through its autoregressive context and uses it to decide both what to say and where to look next.
Action-based Foveation
A special foveation action predicts a continuous visual region, retrieves high-resolution evidence, and inserts it back into the same reasoning stream.
Efficient High-res VLM
The model avoids uniformly expensive high-resolution processing by allocating visual tokens adaptively based on instance difficulty.
Method
Foveated Reasoning treats visual understanding as a sequential decision-making process. Given an initial low-resolution image and an instruction, the model alternates between ordinary language generation and visual focusing actions.
Low-resolution observation
The model first receives a global low-resolution image and the user instruction.
Reason or focus
At each decoding step, the model either emits a text token or triggers a foveation action.
High-resolution evidence
The foveation action predicts a region, retrieves high-resolution visual evidence, and injects it into the context.
Final answer
The model uses both its reasoning history and acquired evidence to produce the final answer.
Results
Foveated Reasoning improves high-resolution visual understanding while using an adaptive visual token budget. The model learns to request more visual evidence for difficult examples and little or none for easy examples.
| Method | uses GT box |
visual token cnt (↓) |
Doc/Text/Chart | General | Relation | Fine | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DocV | TxtC | TxtV | Dude | Sroi | Info | F30k | V7W | GQA | OI | VSR | CUB | |||
| 224² input image resolution | ||||||||||||||
| Sphinx13B | ✗ | 1734 | 19.8 | 55.1 | 53.2 | 0.00 | 7.1 | 35.2 | 60.7 | 55.8 | 58.4 | 46.7 | 61.3 | 50.5 |
| VPT2Btext | ✓ | ≥375 | 12.5 | 53.7 | 46.6 | 10.3 | - | - | 68.0 | - | 60.6 | 84.2 | 65.7 | 89.2 |
| VisCoT7Bmulti | ✓ | 1,152 | 35.5 | 61.0 | 71.9 | 27.9 | 34.1 | 35.6 | 67.1 | 58.0 | 61.6 | 83.3 | 68.2 | 55.6 |
| FoveateR3B | ✗ | 242.3±168.7 | 61.1 | 70.0 | 76.8 | 48.9 | 65.7 | 42.6 | 57.4 | 52.9 | 56.7 | 77.7 | 69.4 | 81.7 |
| FoveateR7B | ✗ | 253.8±162.7 | 73.9 | 76.4 | 83.5 | 55.1 | 73.8 | 51.2 | 59.1 | 58.6 | 64.5 | 83.7 | 74.4 | 87.4 |
| 336² input image resolution | ||||||||||||||
| Llava1.57B | ✗ | 576 | 24.4 | 59.7 | 58.8 | 29.0 | 13.6 | 40.0 | 58.1 | 57.5 | 53.4 | 41.2 | 57.2 | 53.0 |
| Llava1.513B | ✗ | 576 | 26.8 | 61.5 | 61.7 | 28.7 | 16.4 | 42.6 | 62.0 | 58.0 | 57.1 | 41.3 | 59.0 | 57.3 |
| UV-CoT7Bmulti | ✗ | 1,152 | 28.3 | - | 71.1 | 25.3 | 22.7 | 19.8 | 64.9 | 45.5 | 56.8 | - | 55.3 | - |
| VisCoT7Bmulti | ✓ | 1,152 | 47.6 | 67.5 | 77.5 | 38.6 | 47.0 | 32.4 | 66.8 | 55.8 | 63.1 | 82.2 | 61.4 | 55.9 |
| DocThink3B | ✓ | - | 46.0 | 66.3 | 74.6 | 21.3 | 48.6 | 35.5 | 66.4 | 57.2 | 48.6 | 48.5 | 62.5 | - |
| DocThink7B | ✓ | - | 57.9 | 68.2 | 80.2 | 40.8 | 49.5 | 34.7 | 67.4 | 58.0 | 54.6 | 54.2 | 65.6 | - |
| FoveateR3B (ours) | ✗ | 307.0±156.0 | 74.0 | 74.0 | 83.0 | 58.2 | 75.4 | 49.0 | 60.1 | 56.1 | 60.5 | 77.6 | 68.1 | 82.7 |
| FoveateR7B (ours) | ✗ | 322.5±162.7 | 83.3 | 78.3 | 86.2 | 62.7 | 83.2 | 60.0 | 60.8 | 61.3 | 68.2 | 85.5 | 73.9 | 88.6 |
Table 1 from the paper: comparison on the Visual CoT benchmark. Method subscripts denote visual focusing type: multi-pass or text-grounded. Visual token count reports the number of visual tokens used at inference.
BibTeX
Please cite our work if you find it useful.
@article{min2026foveatedreasoning,
title = {Foveated Reasoning: Stateful, Action-based Visual Focusing for Vision-Language Models},
author = {Min, Juhong and Valkov, Lazar and Petsiuk, Vitali and Souri, Hossein and Mohan, Deen Dayal},
journal = {arXiv preprint arXiv:2604.21079},
year = {2026}
}