What's this project about?
We tackle the challenging task of Video Question-Answering (VideoQA). Our goal is to help advance interpretable (modular) systems for multimodal long video reasoning. We make two key contributions:
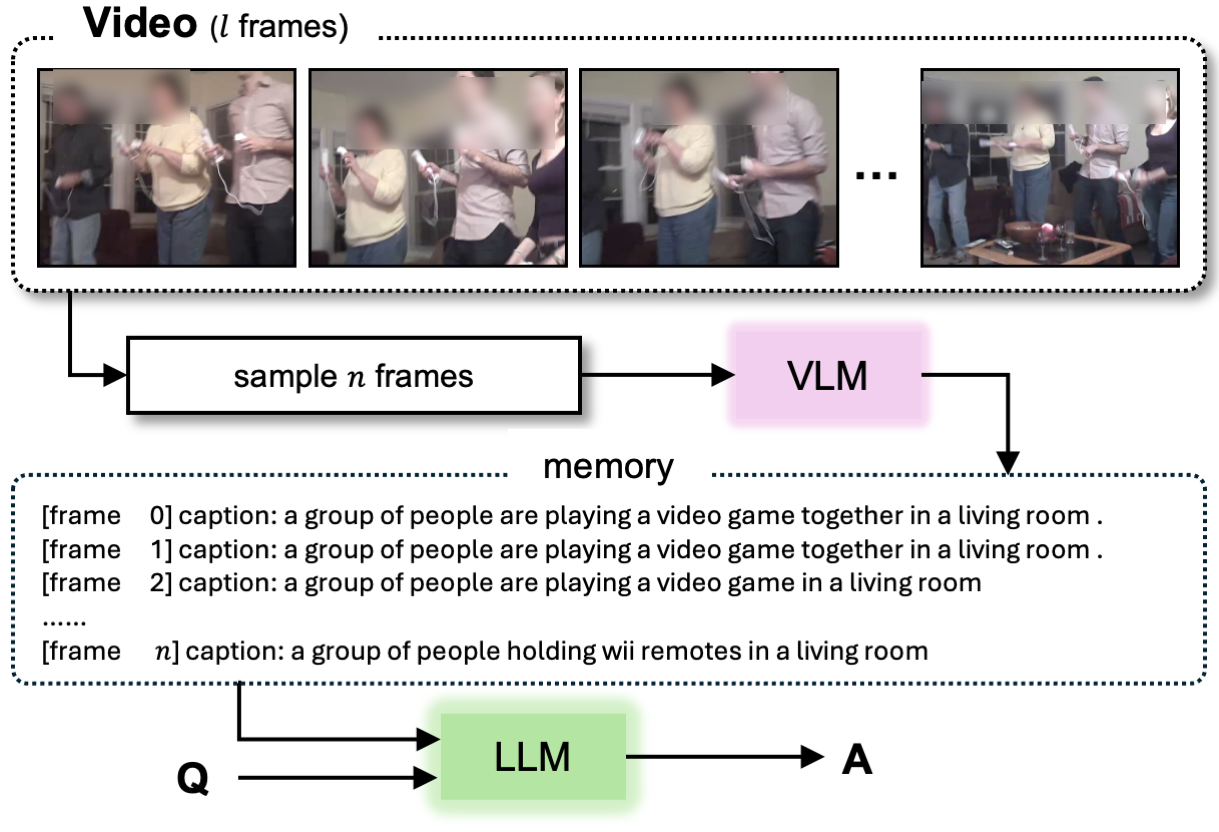
First, we introduce a new “simple program” baseline that just captions every frame (JCEF), and show that it (surprisingly) outperforms state-of-the-art visual programming methods for videoQA! (This means we have a lot of room to improve for visual programming and modular reasoning)
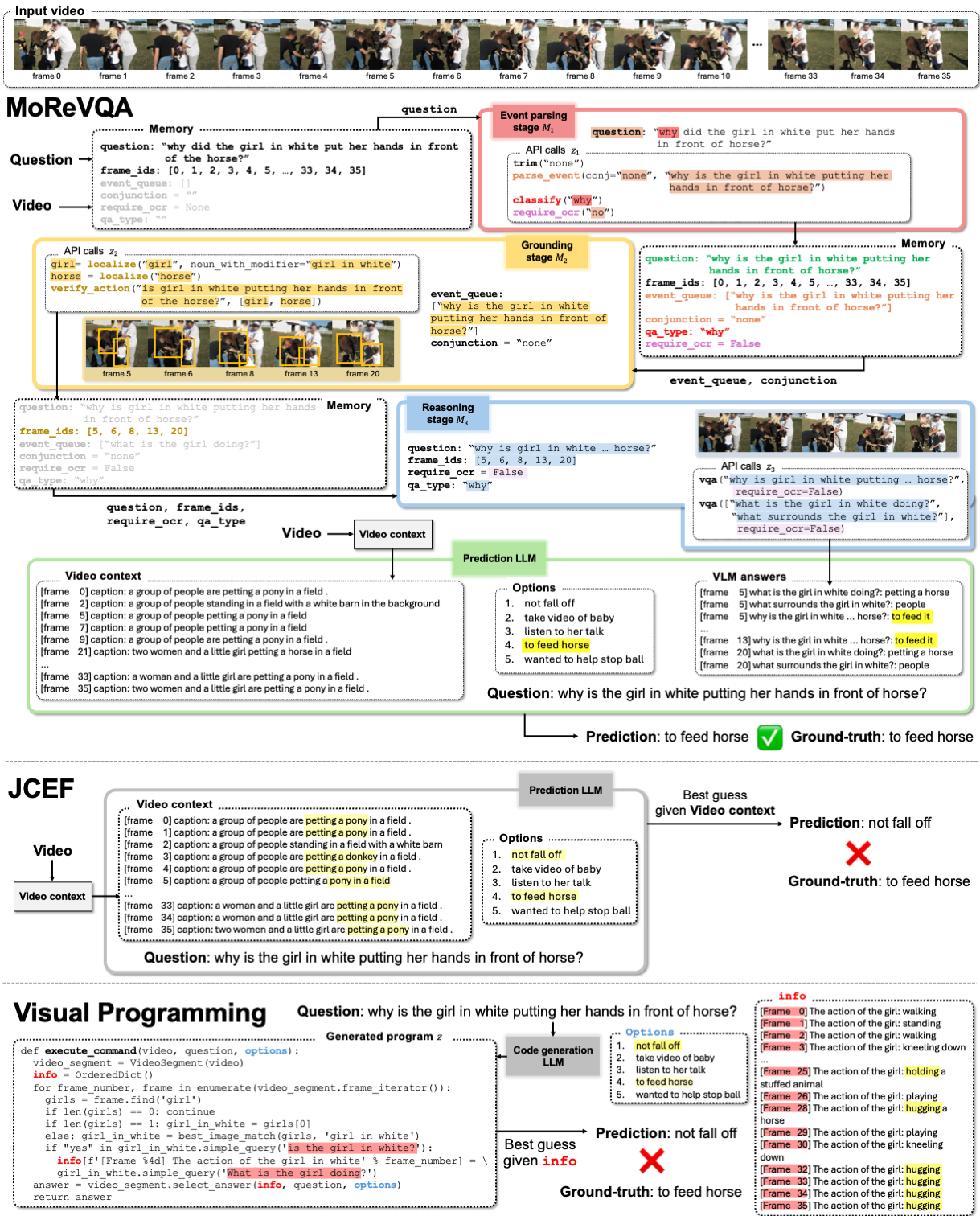
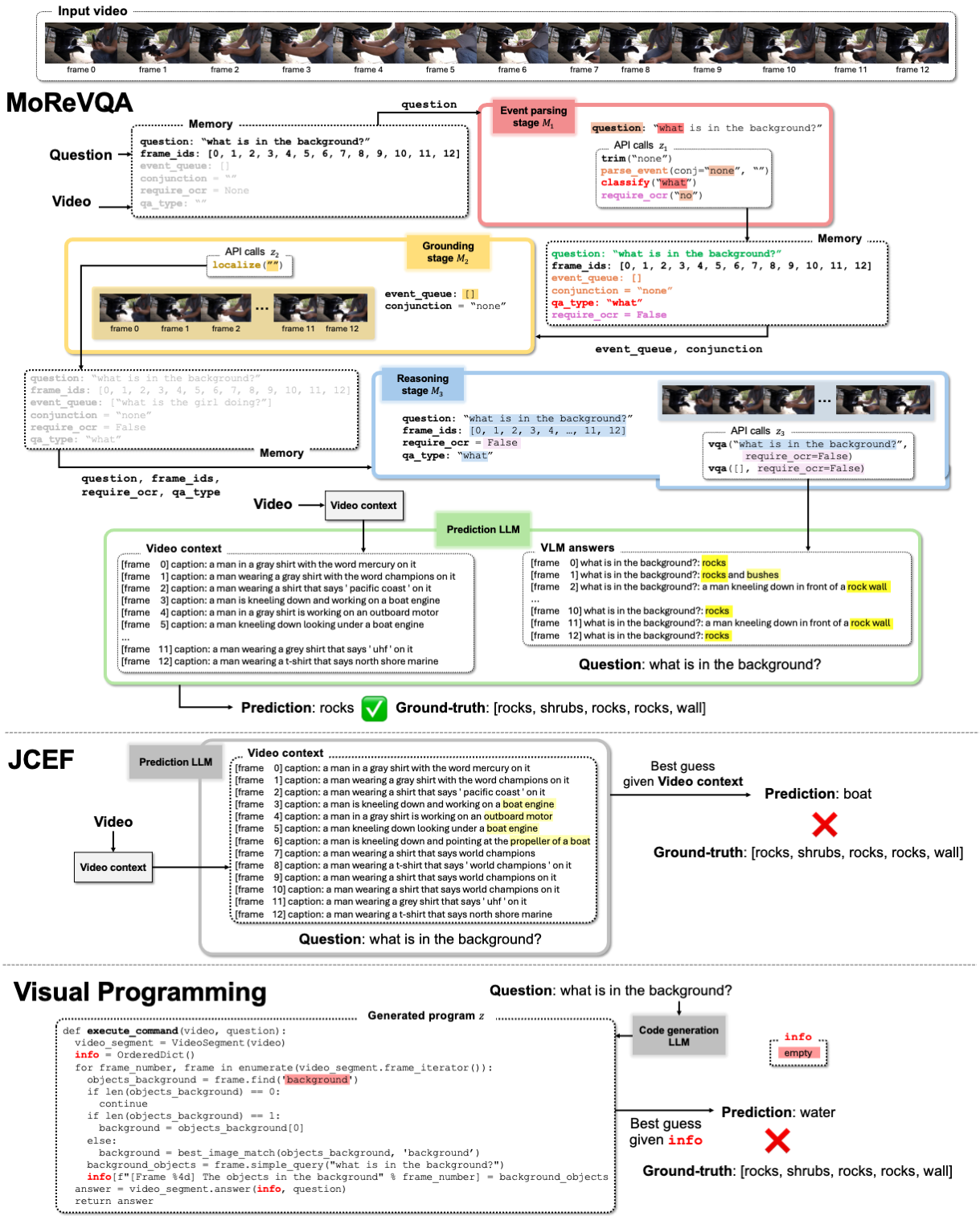
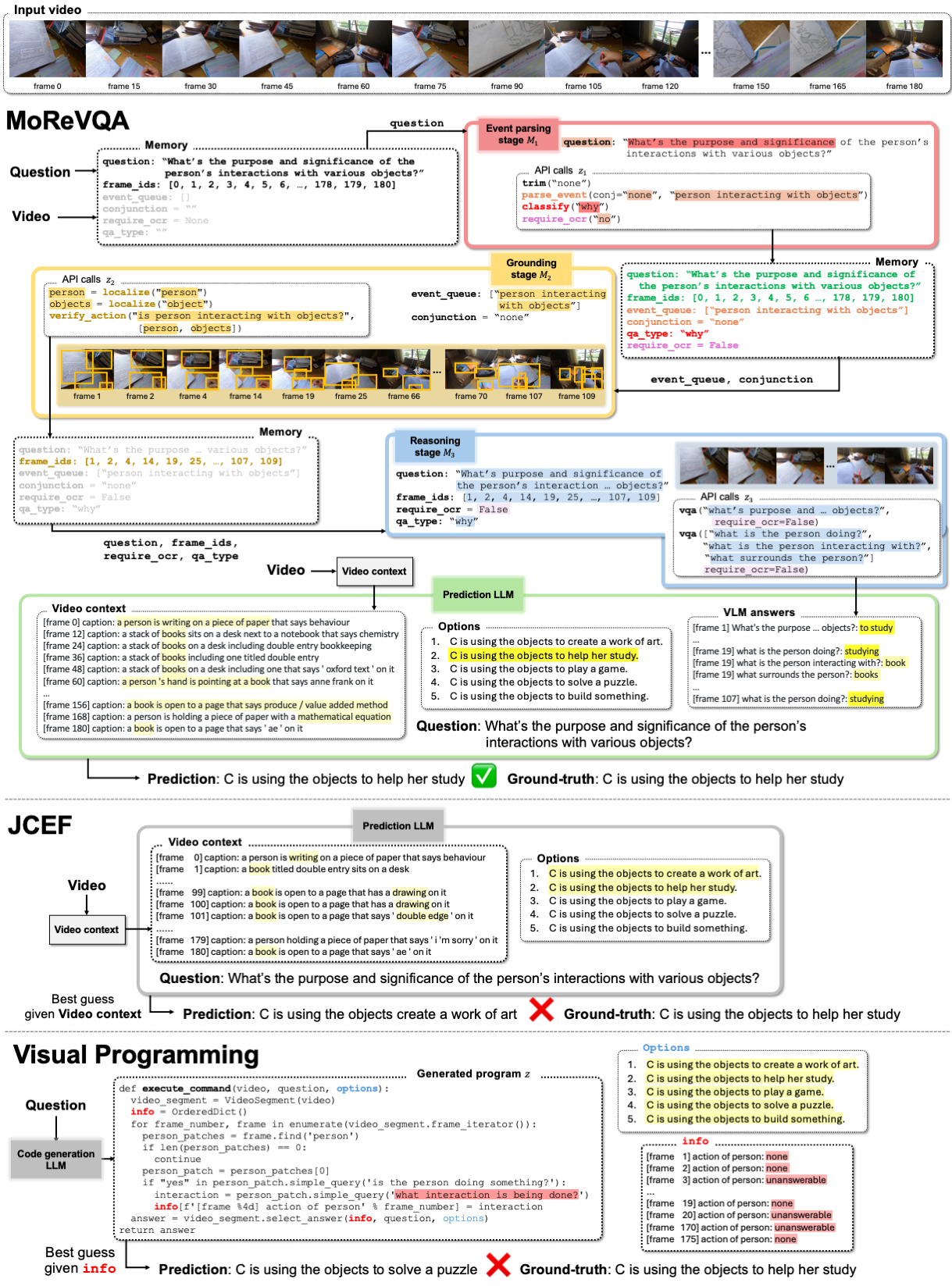
Second, we introduce MoReVQA for multi-stage, modular reasoning for VideoQA. Our method improves over prior single-stage visual programming methods by decomposing the overall task into more focused sub-tasks inherent to video-language reasoning (event parsing, event grounding, and event reasoning). Each stage has its own sub-program generation step (with a flexible API), and all stages are unified with shared memory.
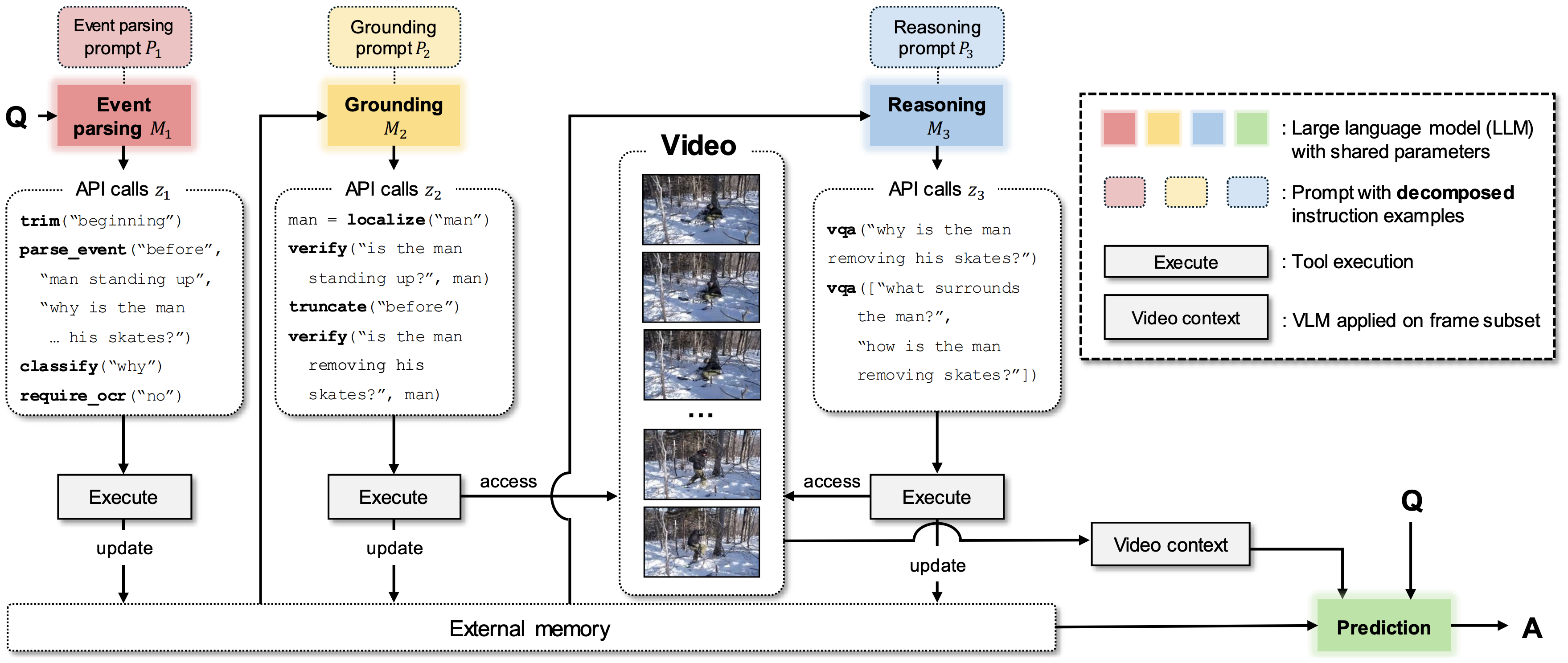
We show that our MoReVQA method improves over prior modular reasoning and visual programming baselines (with consistent base models), and sets a new state-of-the-art across a range of videoQA benchmarks and domains (long videos, egocentric videos, instructional videos, etc.), with extensions to related tasks. To learn more, please see our paper (link).